DATA DICTIONARY INITIAL SCREEN (SE11)
The globally known data types are defined using the
Data Type field.
You can define the type group for creating global constants using the
Type Group field.
The
Domain field is where the technical properties of data objects can be defined.
DATA TYPES IN THE ABAP DICTIONARY
You can generate data objects in the ABAP programs using the data types declared in the ABAP dictionary.
However, an ABAP program cannot access domains for defining data objects. The data elements get their data types from domains.
The components of a structure can be elementary fields, tables, as well as structures.
A structured type or an elementary type can be the line type of a table type (ITAB).
DOMAIN
Domains cannot be used directly in programs or tables.
Therefore, data element is used as a bridge from the technical properties to the different data types or data objects.
You can define technical attributes and value ranges.
The most frequently used data types are CHAR, DATS, DEC, and NUMC. CHAR, the character string, can have a maximum length of 255 in tables. DATS defines the date and the length is set at eight characters.
DEC is used for the calculation of an amount in a field, and contains operators, such as the point, the plus or minus (+/-) sign, and thousand-separator commas. It can have a maximum of 31 characters.
NUMC is used for character strings that comprise only numbers. It is restricted to a maximum of 255 characters.
DATA ELEMENT
Data elements not only constitute the link between domains and the data objects, but also contain semantic or technical information about the data objects created from these.
You can translate the field labels into other languages by choosing the transaction SE63 or the menu path:
Goto → Translation.
You can append F4 or input help to a data element.
You can assign the SET or GET parameter to the data element, if an input field based on the same data element exists on a subsequent screen. This helps you read the value from the parameter and enter it in the screen field.
STRUCTURES
Structure components can be data elements, integrated types, structure definitions of internal tables, DB table views, or other existing structure definitions. The data object, generated by including the fields of an actual two-dimensional object like a view or DB tables, remains flat or one-dimensional.
USING SIMPLE STRUCTURES IN ABAP
A flat structure is formed by the sequence of fields through the use of data elements. A one-dimensional data object is formed with this structure type. The individual elements or components of the structure can be addressed by using the name of the structure, a hyphen, and the name of the components.
NESTED STRUCTURE
A nested structure is formed by including another structured object in the structure and assigning it to a component.
You can nest structures like these into one another in any way.
INTERNAL TABLES
Internal tables can be defined using an existing line structure. You can use database tables, structure definitions, views, data elements, direct type definitions, or existing table types as line types.
A two-dimensional array is created in the main memory by declaring an internal table in an ABAP program.
DEEP STRUCTURE
A deep structure is formed by inserting an internal table as a structure component. It contains at least one table. The component of such a table has its own name and can be addressed like a normal internal table (LOOP AT..., INSERT... INTO TABLE, ...).
An internal table can have a deep structure as a line type. Thus multidimensional data types can be created as you can inter-nest internal tables and structures several times.
TYPE GROUP
You declare the type group using the TYPE POOL statement. This enables you to use the types of a type group in a program.
All names of these data types and constants must begin with the name of the type group and an underscore.
You define global constants using a type group, which should have a name not more than five characters long.
In the type group, you use the CONSTANTS statement to define constants, as well as to declare cross-program constants.
TABLES AND FIELDS
A table consists of

columns (fields) and rows (entries);
a unique table name and certain general attributes, such as delivery class and maintenance authorization; and
certain key fields called the primary keys, whose values uniquely identify each entry of the table.
BASIC OBJECT OF THE ABAP DICTIONARY
The basic objects for defining data in the ABAP Dictionary are
tables
data elements, and
domains.
Domains are used for technical definition of table fields, such as field type and length. One domain may be used by more than one data element.
Data elements, on the other hand, are used for semantic definitions, such as short descriptions. One data element may be used by more than one field of one or more tables.
A field in a table is not an independent object. It is table-dependent and can only be maintained within a table.
TWO-LEVEL DOMAIN CONCEPT: EXAMPLE
A single domain can be used for different data elements.
Let us assume that flight schedules are stored in a table SPFLI. The table contains the fields AIRPFROM (departure airport) and AIRPTO (arrival airport). These fields have the same domain S_AIRPID because both fields contain airport IDs and therefore have the same technical attributes.
They have a different semantic meaning, however, and use different data elements to document this. The field AIRPFROM uses data element S_FROMAIRP while field AIRPTO uses data element S_TOAIRP.
TRANSPARENT TABLES AND STRUCTURES

A transparent table is automatically created on the database when it is activated in the ABAP Dictionary. When this happens, the database-independent description of the table from the ABAP Dictionary is translated into the language of the corresponding database system.
The database table thus created, along with its fields, has the same name as the table in the ABAP Dictionary. The data types in the ABAP Dictionary are converted to the corresponding data types of the database system.
The order of the fields in the ABAP Dictionary can differ from the order of the fields on the database.
Transparent tables can be accessed by ABAP programs in two ways:
Access the data in the table with the OPEN SQL or the EXEC SQL command.
Access a structured type defined in the table, only when variables or more complex types are defined.A structured type, for which there is no corresponding object in the database, can also be created in the ABAP Dictionary. Such types are called
structures. Structures can also be used to define the types of variables.
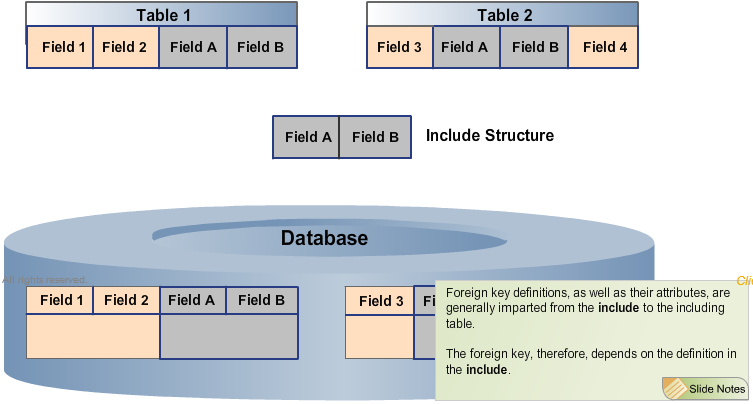
To avoid redundant structure definitions, you can include structures in tables or within other structures. A table can only be included in its entirety.
A chain of
includes may only contain one database table.
An
include can contain other
includes.
TECHINCAL SETTINGS
Technical settings help determine how to manage the tables once they are created on the database; whether they should be buffered; and whether modifications to the entries should be logged.
Once a table is activated in the ABAP Dictionary, it is automatically created in the database. You can deduce the information on storage area and expected table size from the settings for the data class and size category. The buffer settings specify how the table should be buffered, if necessary. You can also define whether modifications to the table entries should be logged.
FRAGMENTING THE TABLES IN THE DATABASE
One way to defragment the indexes is to simply delete and reenter them. The database once again calculates the content and structure of the index, and creates a single memory space, where possible, in the storage medium. During this process, you can still use the database tables.
You can reduce fragmentation in fragmented tables by converting them. All the data is first transferred to a new table created by the SAP system. The old table is deleted and replaced by the new one. If the new table grows unexpectedly and quickly, it is also checked again, before being converted.
DATA CLASS
A data class logically defines the physical area of the database in which your table should be stored. If defined correctly, tables will automatically be created in the right areas on the database, when they are activated in the ABAP Dictionary.
The four main data classes are
master data,
transaction data,
organizational data, and
system data.
Master data is rarely modified. One example of master data is an address file, with a name, an address, and a telephone number.
Transaction data, on the other hand, is frequently modified. An example of transaction data is the material stock of a warehouse, which can change after every purchase order.
The third main data class, organizational data, is defined during Customizing when the system is installed. It is rarely modified after that. Country keys are examples of organizational data.
The last data class, system data, is the data required by the SAP System itself. Program sources are examples of system data.
SIZE CATEGORY
The size category describes the expected storage requirements for a table in a database.
When a table is initially created in the database, a fixed extent is reserved for it, irrespective of its size category. If more space is required later, additional extents can be added. The sizes of these additional extents are fixed and are determined by the size category specified in the ABAP Dictionary.
Size categories range from 0 to 4.
LOGGING
Logging is used to record and store modifications to the entries of a table.
However, this option is available only if the SAP System contains the parameter
rec/client, which can be set to different values to define which clients have log access.
Data modifications are logged independently of the update.
OVERVIEW OF THE DB TABLES TYPE
Pooled and cluster tables are other database table types.
The definition of transparent tables is identical in both the ABAP Dictionary and the database. In contrast, pooled and cluster tables comprise several tables, which are logically defined in the ABAP Dictionary, but are combined into a single physical database table.
CLUSTER TABLES
Cluster tables store functionally dependent data, divided among different tables, in a single database table. The intersection of the key fields of the cluster tables, or the key of the table cluster, is called the cluster key.
Data dependent on a single cluster key is stored in the VARDATA field of the table cluster.
The database interface also compresses the contents of the VARDATA field. The latter, therefore, includes a description for decompressing its data.
The PAGNO field of the cluster table ensures that all entries are unique; while the TIMESTAMP and PAGELG fields contain administrative information.
POOLED TABLES
Table pools, unlike the table clusters, store data records from independent tables defined in the ABAP Dictionary.
This example depicts the intersection of the key fields of TABA and TABB, which is empty. Despite this difference, the data records from TABA and TABB are stored in a single database table, the TABAB table pool.
The key for a data record of the TABAB table pool consists of a combination of the fields TABNAME and VARKEY.
The TABNAME field assumes the name of the pooled table.
The VARKEY field comprises the key fields of the pooled table.
The VARDATA field contains the non-key fields of the pooled tables, stored in an unstructured way. These are also compressed by the database interface. The length of the VARDATA field is stored in the DATALN field.
DESCRIBE THE ADVANTAGES AND DISADVANTAGES OF POOLED AND CLUSTER TABLES
Pooled and cluster tables contain far fewer tables, as a direct result of the combination of tables and of data compression.
This translates into fewer different SQL statements.
The main disadvantage of pool and cluster tables is the limited database functionality. There is no support for primary or secondary indices, database views, ABAP JOINs, or Table Appends. Moreover, the data in these tables can only be accessed through OPEN SQL .

 In the ABAP Dictionary, information about a structure or table is stored in data elements and structure definitions. The runtime object combines this information into a structure which is so designed that it can be easily accessed from ABAP programs.
In the ABAP Dictionary, information about a structure or table is stored in data elements and structure definitions. The runtime object combines this information into a structure which is so designed that it can be easily accessed from ABAP programs.















 the size of the table to be buffered;
the size of the table to be buffered;